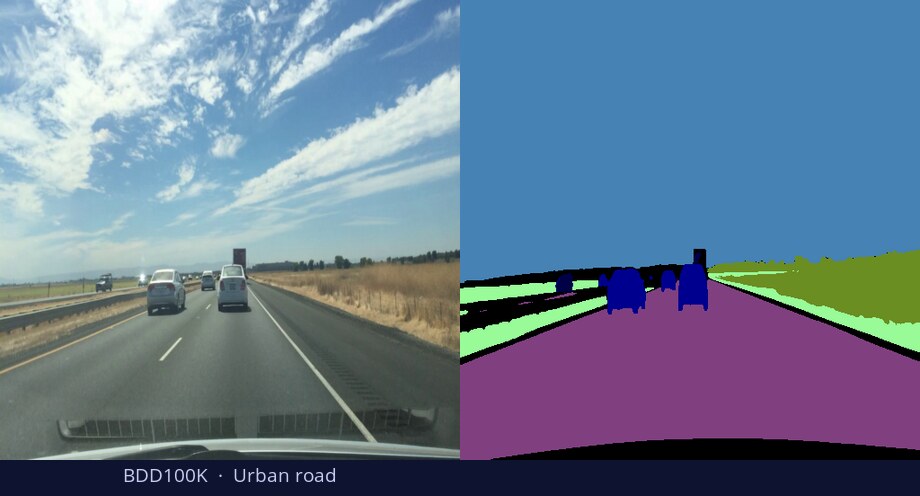
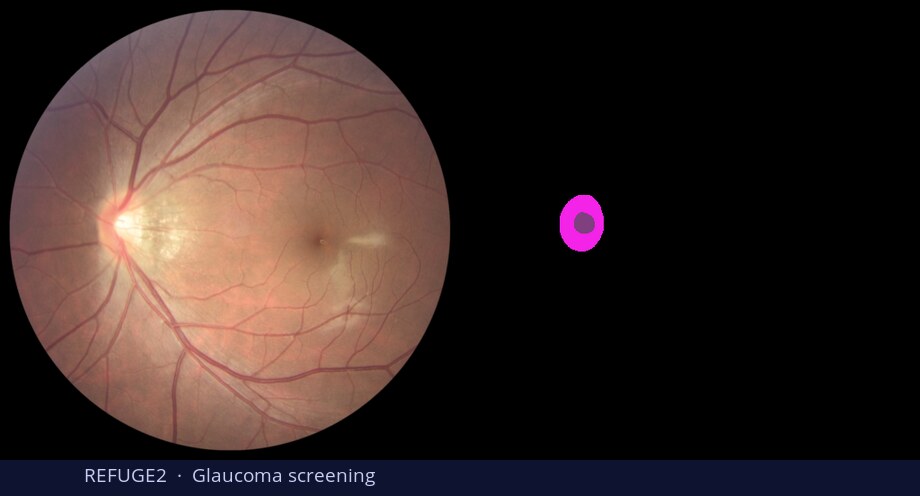
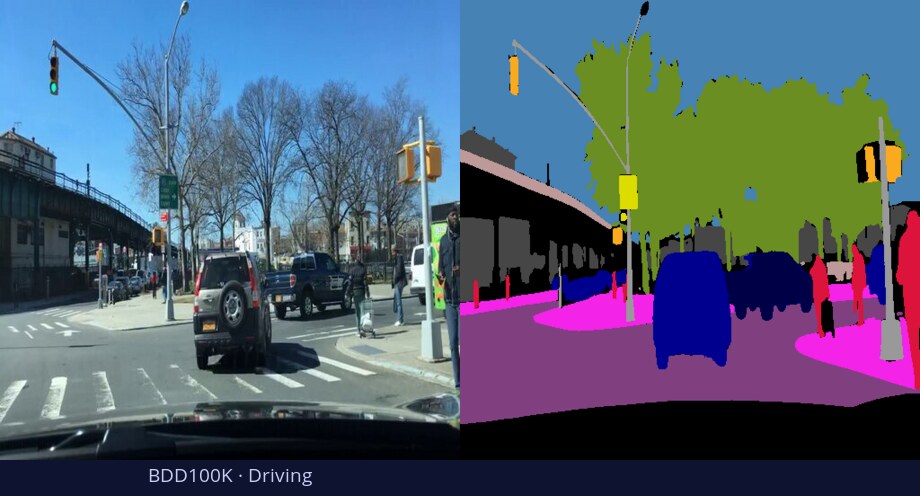
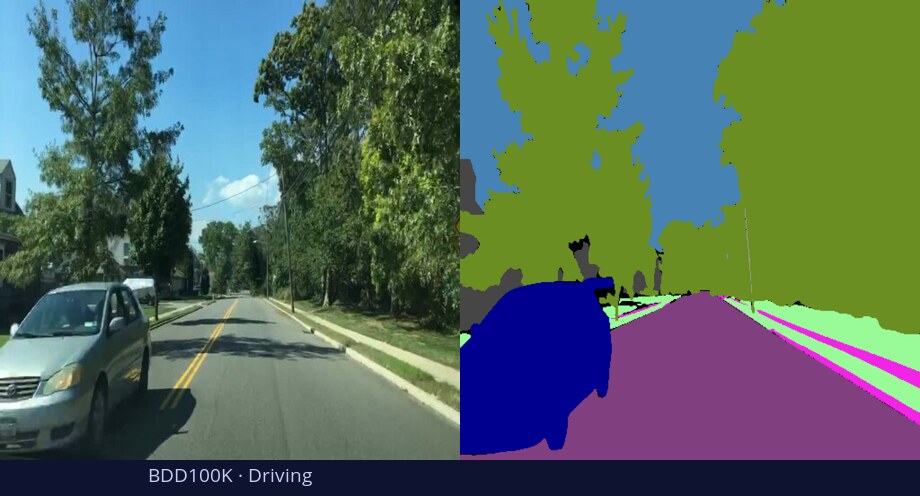
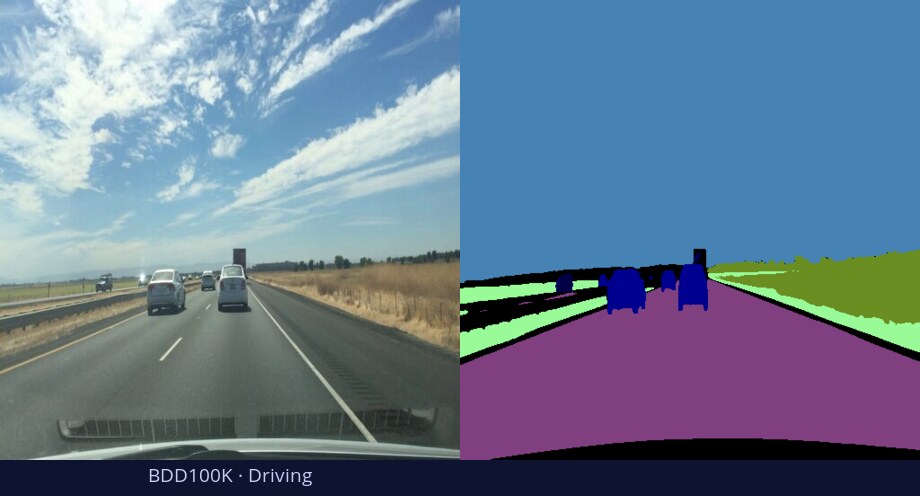
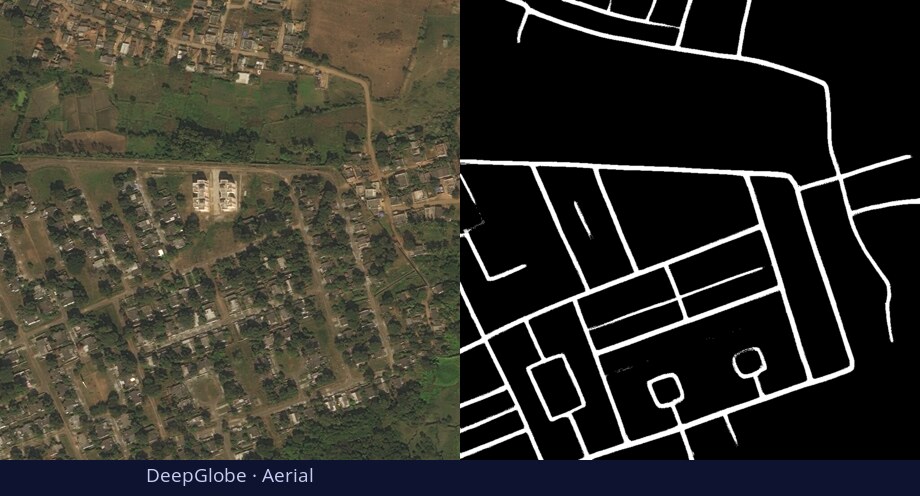
What is DiGSeg?
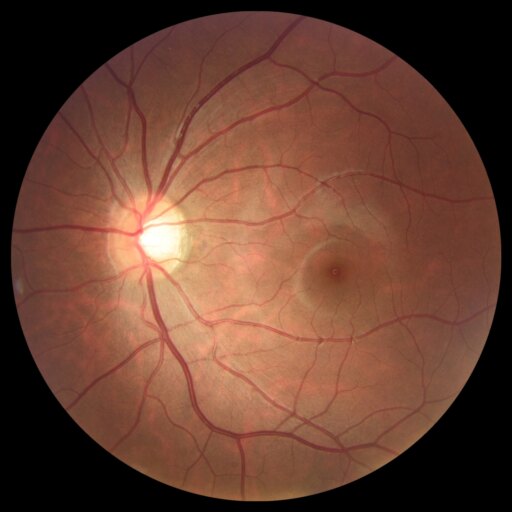
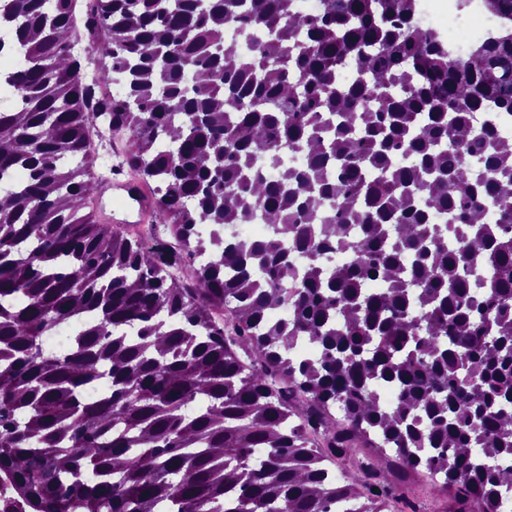
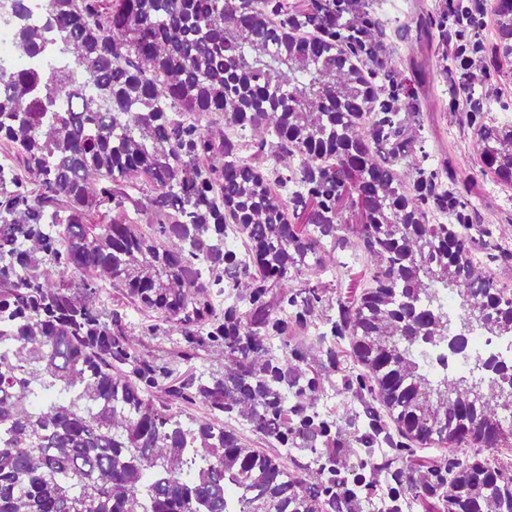
TL;DR: DiGSeg repurposes a pretrained diffusion model into a single generalist segmenter, driven by text prompts for semantic and open-vocabulary segmentation — reaching state-of-the-art on standard benchmarks and transferring across domains (medical, remote sensing, agriculture) with no domain-specific architecture changes.
State-of-the-art segmentation
SOTA on standard semantic segmentation, with strong open-vocabulary and cross-domain transfer.
Diffusion priors for segmentation
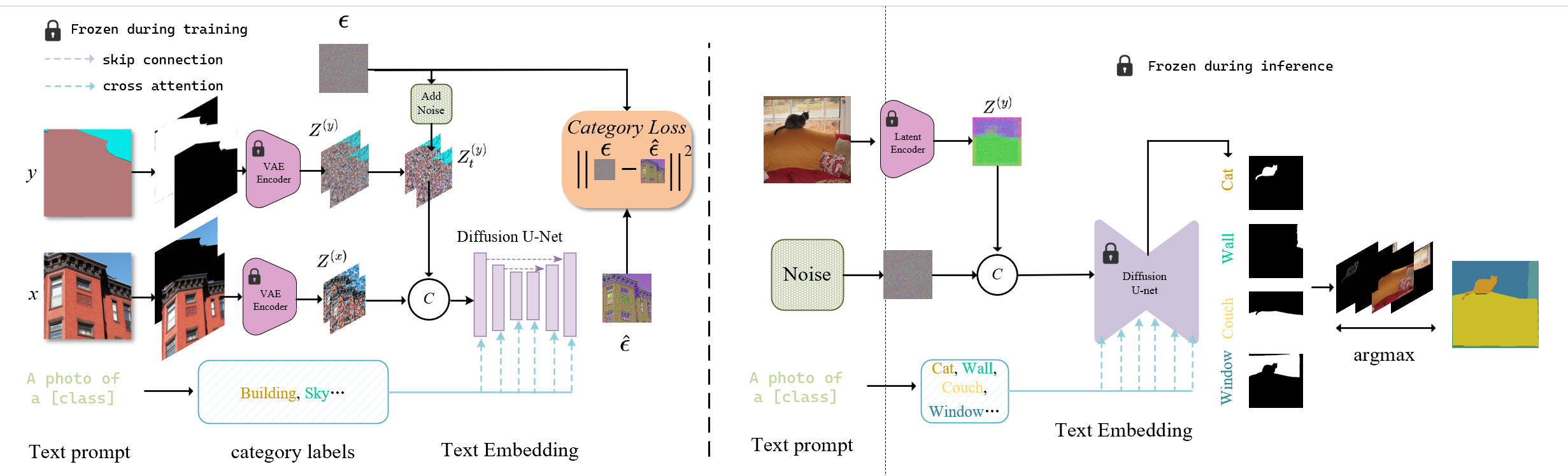
Repurposes a pretrained diffusion U-Net, conditioned on image latents and a CLIP-aligned text pathway.
Generation meets understanding
One diffusion backbone generalizes across tasks and domains—no per-domain architecture changes.
Abstract
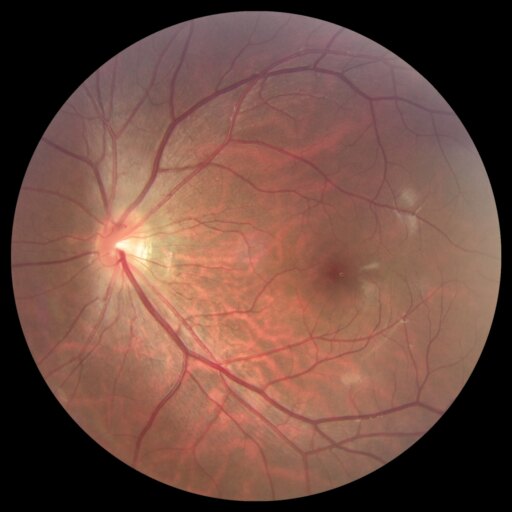
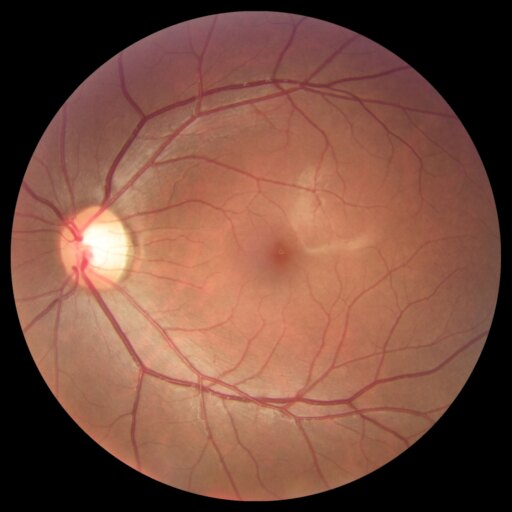
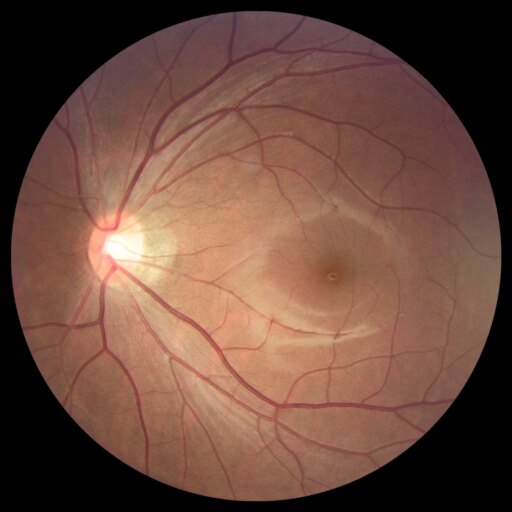
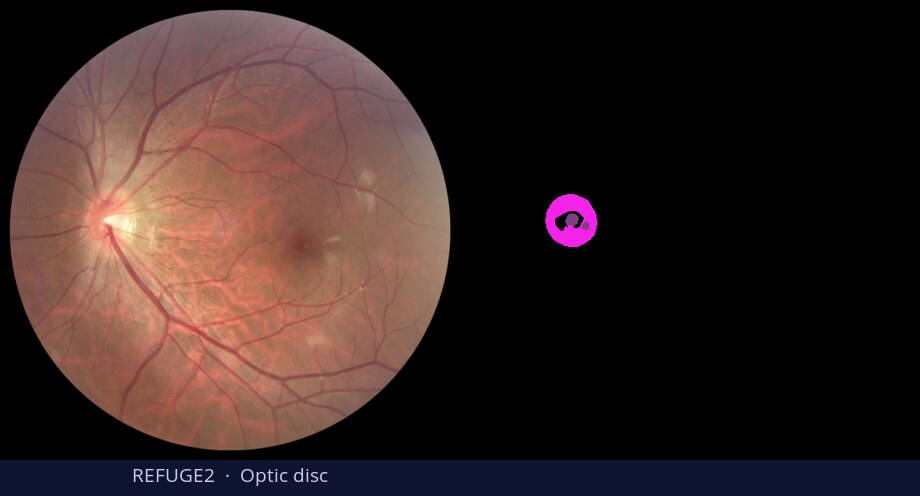
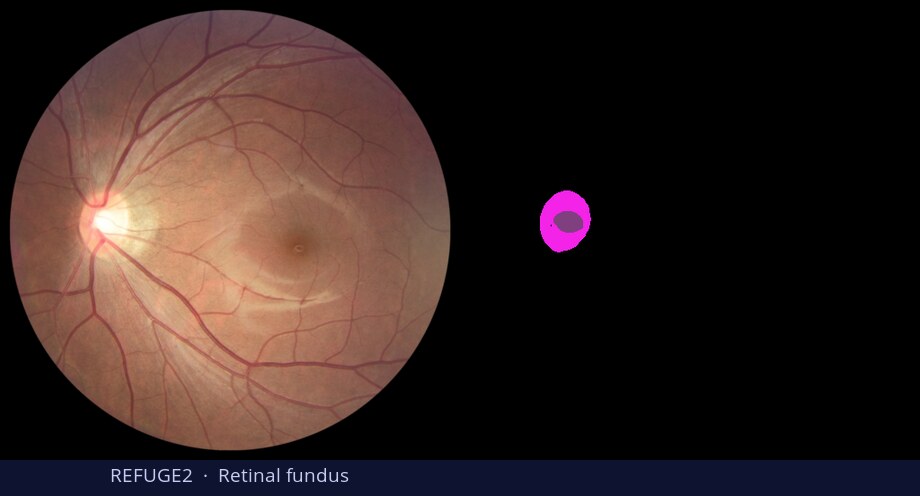
Diffusion models are primarily trained for image synthesis, yet their denoising trajectories encode rich, spatially aligned visual priors. In this paper, we demonstrate that these priors can be utilized for text-conditioned semantic and open-vocabulary segmentation, and this approach can be generalized to various downstream tasks to make a general-purpose diffusion segmentation framework. Concretely, we introduce DiGSeg (Diffusion Models as a Generalist Segmentation Learner), which repurposes a pretrained diffusion model into a unified segmentation framework. Our approach encodes the input image and ground-truth mask into the latent space and concatenates them as conditioning signals for the diffusion U-Net. A parallel CLIP-aligned text pathway injects language features across multiple scales, enabling the model to align textual queries with evolving visual representations. This design transforms an off-the-shelf diffusion backbone into a universal interface that produces structured segmentation masks conditioned on both appearance and arbitrary text prompts. Extensive experiments demonstrate state-of-the-art performance on standard semantic segmentation benchmarks, as well as strong open-vocabulary generalization and cross-domain transfer to medical, remote sensing, and agricultural scenarios—without domain-specific architectural customization. These results indicate that modern diffusion backbones can serve as generalist segmentation learners rather than pure generators, narrowing the gap between visual generation and visual understanding.